I just finished up my first semester in the Duke MIDS program, and one of my favorite classes was Modeling and Representation of Data. During this class, we learned about modeling techniques, assumptions, and how to interpret the results. We applied these techniques in weekly assignments, but we also worked throughout the semester on a final modeling project of our choice. With my background and interest in healthcare, I decided to focus on nursing homes for my analysis.
In my research, I found that measuring and validating clinical quality in elderly health has been a challenge in the industry, so I wanted to look into this further in my modeling project. Ideally, I would have liked to build a model using nursing home characteristics to predict individual health outcomes, but it is close to impossible to obtain publically available individual-level health data. Thus, I found the Medicare Nursing Home Compare data (available here), which provides the Medicare quality metrics for 15,613 nursing home providers across the United States. I focused on 6 outcome measures defined by the CMS: 3 long-stay and 3 short-stay. For my predictor variables, I decided to use another Medicare dataset that contained information about these same nursing homes (available here), and which could be linked together using a Provider ID.
I decided to try three different modeling techniques: linear regression, multiple logistic regression, and multinomial logistic regression. For the linear regression, I chose to maintain the quality metrics as percentages and predict on them as continuous variables. For the logistic regression model, I created a binary flag to indicate whether the nursing home provider was in the top half/bottom half of the population in performance. And for the multinomial logistic regression, I created a scorecard and gave each provider a score accordingly (A: Top 25%, B: 50–25%, C: 75–50%, D: Bottom 25%).
I created these three models for each of my six outcomes, and I quickly found that the linear regression models were not useful. For the logistic and multinomial logistic models, I felt that it would be more clinically relevant to find out which factors were most important in predicting positive health outcomes, so I ranked the predictors across all of the six outcomes and calculated the weighted average. The full modeling workflow is shown below.
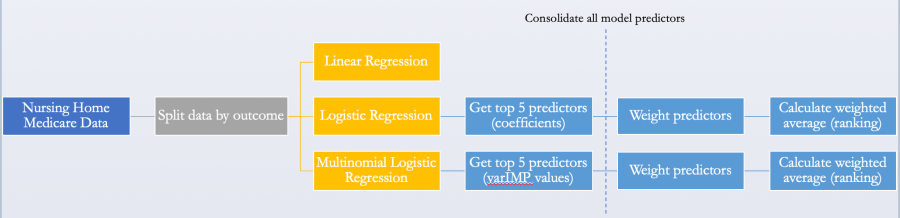
I then plotted these weighted averages/rankings to see how the important predictors varied across long stay vs. short stay outcomes, as well as across logistic vs. multinomial logistic modeling. These results are shown below.
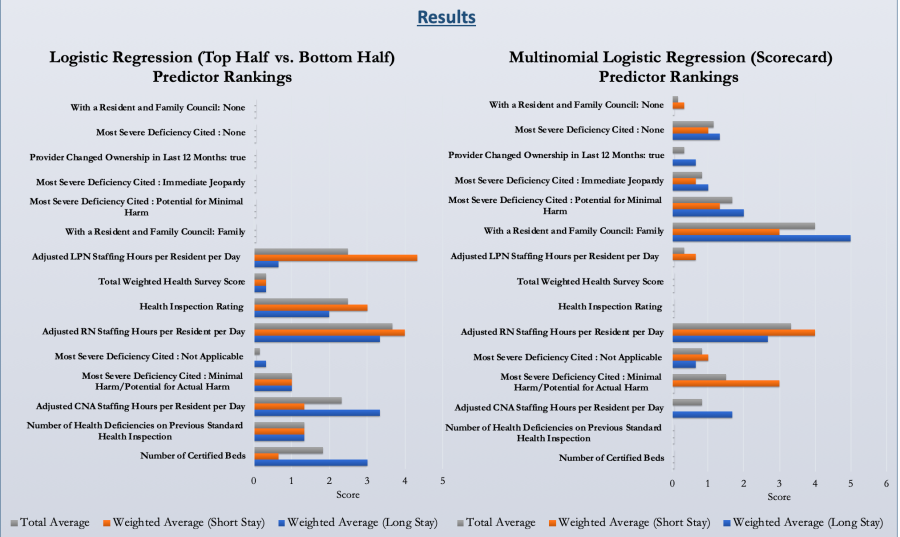
From these results, we can see that overall, nursing staffing seems to be the most predictive of positive health outcomes, which lines up with previous research and conventional thinking. But from our logistic regression model, LPN staffing is more important for short stay outcomes, while CNA staffing is more important for long stay outcomes, with RN staffing being important in both.
In our multinomial logistic regression, we can see that different predictors show up as important. Notably, the most important predictor across both short and long stay outcomes is the presence of a Family council. In nursing homes, a family council is a group of family members of residents who meet and talk about ways to improve the nursing home. It makes sense that this also predicts high clinical quality, since this allows staff to directly learn from an outside voice about ways to improve their care. RN staffing hours were also important in this model.
Overall, this was an interesting analysis that taught me a lot about nursing homes and how to model Medicare data. The aim of this project was to build a framework that nursing home providers could use to identify their strengths and weaknesses, as well as figure out which areas to contribute their care management resources to in order to improve their healthcare delivery. As more healthcare data is collected and quality metrics continue to be evaluated, this framework can be adapted and improved to include more predictors and more health outcomes. I hope to learn more about this area in the future, and hopefully can build upon this work by integrating patient-level data.
All of the data and code used in this project are published in my Github repository, as well as my notes and final research poster.
https://github.com/vkumaresan/Nursing-Home-Analysis
Originally published at http://datainallthings.wordpress.com on January 10, 2019.